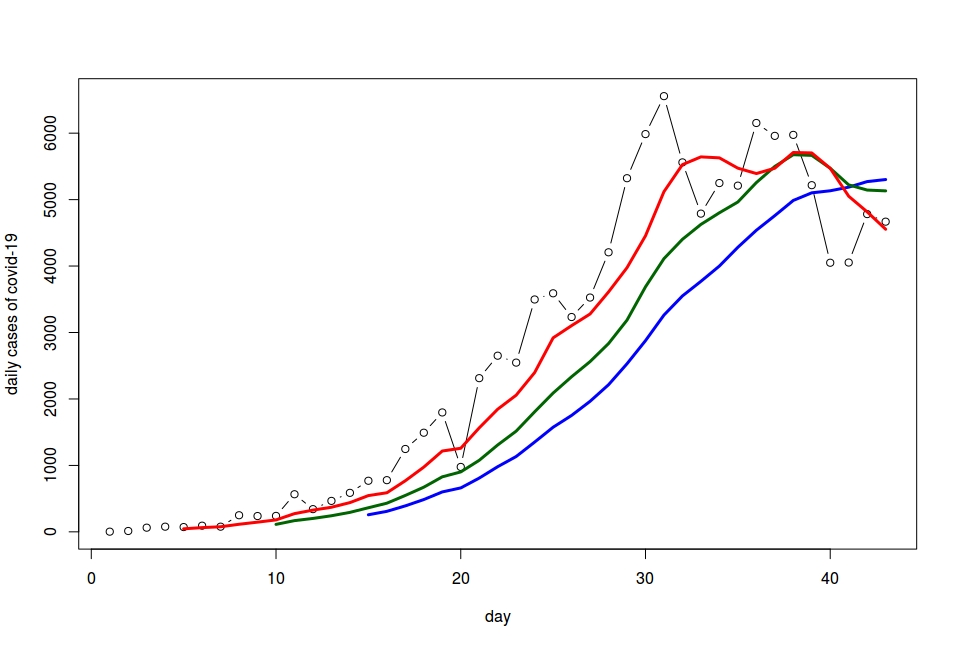
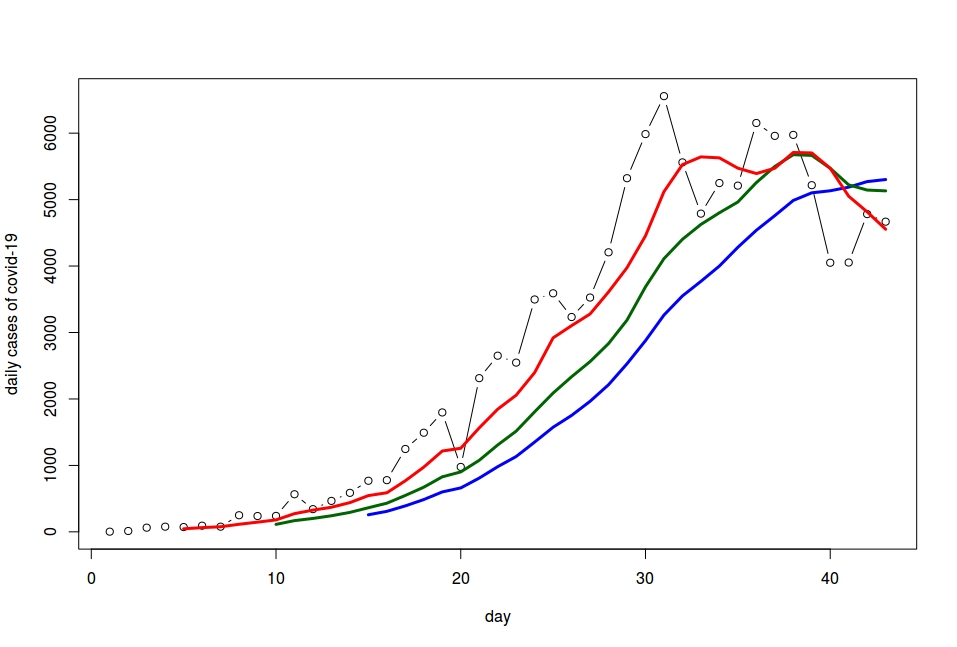
We just wanted to comment on a marginal point that seems to have gone unnoticed. Citing an ISS study, the premier said that one out of four infections occurs in the family. The ISS study is summarized in this link:
https://www.epicentro.iss.it/coronavirus/bollettino/Bollettino-sorveglianza-integrata-COVID-19_23-aprile-2020.pdf
and needless to say, it is well done.
Its interpretation, however, requires some more caution than that shown by some newspapers that have taken it up. The study reports that 44.1% of infections occurred in RSA, 24.7% in the family setting, 10.8% in hospital or day-hospital, and 4.2% at work. Of the remaining cases, for many, it was not possible to establish the context in which the infection occurred.
Does this mean that of all the infections, one in four is in the family? No.
There are two types of distortions that need to be considered. The first type is the sampling distortion. Several RSA monitoring campaigns have rightly been launched in various regions. If the positives are searched in RSA, it is normal that many of the positives found will be in RSA. Therefore, not only in reading these percentages is it possible to forget that they concern only those diagnosed, and not the entire population of patients who would be positive for the swab; but also the fact that the place of infection can be indicative of the probability of diagnosis. RSA patients are fragile, the more easily they will develop symptoms, and therefore the more easily they will be diagnosed. A diagnosis rightly leads to the monitoring of the entire structure, which does not happen (unfortunately) for many workplaces.
The second source of distortion is the missing information: for the reasons above, patients whose context is unknown are more likely to have had an infection at the workplace or in the supermarket than the RSA itself.
Another fundamental aspect is that the table is built on data collected only in April and therefore with the whole country in lockdown. In this case, the workplaces are not frequented at all and therefore cannot be places of contagion for many.
We conclude by asking once more that the individual data, in the availability of the ISS and the ASP, be shared with the researchers. In fact, it is possible to use appropriate statistical techniques that correct the percentages reported above for the distortion, giving more reliable estimates of the contagion contexts.